Beim 31. Chaos Communication Congress, auch 31C3, wurde ein neues Projekt von Tactical Tech gelauncht: Trackography. Ich war ganz am Anfang im Sommer auch Teil des Teams, aber das Ergebnis, das jetzt vorgestellt wurde, ist das Ergebnis der Arbeit von anderen.
In einem Satz: Trackography (Betonung auf der 2. Silbe) zeigt, wo Eure Daten landen, wenn Ihr News-Websites lest. Durch welche Länder (= deren Geheimdienste), über welche Server und zu welchen Firmen die Information wandert, für welche Nachrichen Ihr euch interessiert. Der geringste Teil davon sind die Server von Berliner Zeitung, Washington Post oder Guardian.
Ihr könnt auf trackography.org auswählen, welche News Ihr lest und dann auf einer Karte beobachten, wie sich Eure Informationen durch’s Netz bewegen.
Sehr cool fand ich, dass Maria Xynou und Claudio Agosti das am Montag an einem aktuellen Beispiel vorgeführt haben:
Am Abend vorher hatten Laura Poitras und Jakob Applebaum ebenfalls beim 31C3 neue Snowden-Dokumente präsentiert, die gleichzeitig bei Spiegel Online veröffentlicht wurden: Inside the NSA’s War on Internet Security. Sie bestätigten damit, dass viele vielbenutzte Methoden zur Verschlüsselung im Internet von der NSA geknackt werden können. Als Marias am Montag fragte, wieviele den Spiegel-Artikel während des Talks ohne den Anonymisierungsdienst Tor angeklickt hatten, hoben sich viele Hände.
Und Trackography führte vor, wem sie damit ihre Daten frei Haus geliefert hatten:

spiegel.de – Prying Eyes: Inside the NSA’s War on Internet Security
Eure Daten – also Daten über Euren Browser, Euer Surf-Verhalten, den Rechner/das Smartphone oder Tablet und verschiedenes anderes, das ausreicht, um euch jeweils persönlich zu identifizeren, das ist hinreichend nachgewiesen – werden im Fall von Spiegel Online von 37 anderen Instanzen aufgezeichnet. Sie wandern über die Niederlande, Großbritannien, Dänemark, Spanien und die USA.
Für die verschiedenen Tracker gibt’s eine Tabelle, die auflistet, welche spezifischen Probleme sie mitbringen: Dauer der Vorratsdatenspeicherung in dem Land, in dem sie sitzen; unterstützen sie die Initiative ‚Do Not Track‚ (oder nicht), betreiben sie Profilbildung mit den Daten.
Die Arbeit an Trackography begann letzten Sommer und das Team hat wirklich Erstaunliches geleistet. Einiges fehlt noch, hier bspw. Infos über die Tracker plista, Admeta und Meetrics, aber für die anderen gibt es ausführliche Übersichten und dazu jeweils auch noch Erklärungen: was bedeutet Profiling, was ist Do Not Track, etc.
Im Fall des Spiegel-Artikels fällt bspw. auf, dass die Daten auch in Spanien getrackt werden, und wenn ich in der interaktiven Grafik Spanien anklicke, erscheint die Erklärung, dass dort der Server i.ctnsnet.com beheimatet ist. Coookiepedia hat nicht viele Informationen über ctsnet.com außer der, dass es viele Cookies von dort gibt, aktuell 1445, die auf 662 verschiedenen Websites zu finden sind. Hier gibt es also auf jeden Fall die Möglichkeit, viele Informationen über viel Menschen zusammenzuführen.
Die Grafik zum NSA-Krypto-Artikel bei Spiegel Online ist nicht online. Alles andere aber schon und was verblüfft ist, dass das Ergebnis für spiegel.de anders ausfällt. Hier gibt es kein Twitter und Facebook, soweit wenig überraschend, denn die finden sich jeweils bei den Artikeln zum weiterverteilen. Aber warum die Daten statt in Spanien, wie bei der Spiegel-Hauptseite, jetzt in Italien vorbeikommen, müsste wohl Spiegel Online erklären:
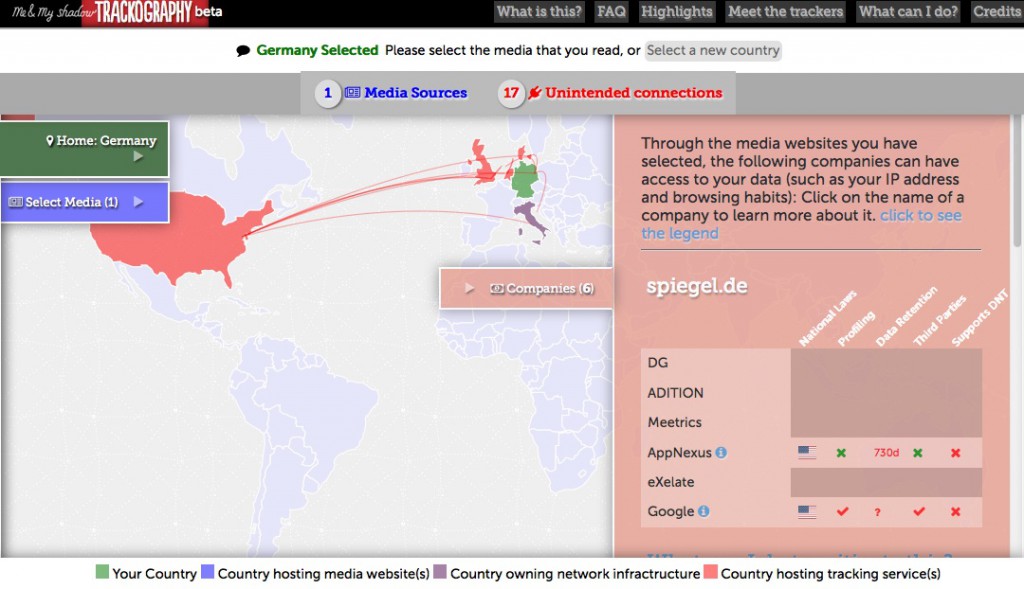
Spiegel.de
Hier haben wir stattdessen auch andere Werbefirmen, etwa AppNexus, die alle Daten volle zwei Jahre auf Vorrat speichern.
An diesem Punkt startet gewöhnlich die Debatte darüber, wie denn sonst Online-Journalismus finanziert werden soll? Ich weiß es auch nicht. Wenn ich das wüsste, würde ich aktuell was anderes machen, als hier rumzubloggen.
Trackography hat News-Websites als Beispiel genommen, weil das Ziel dieses Projekts ist, normalen Userinnen und Usern deutlich zu machen, was Tracking bedeutet. In der Annahme, dass die meisten Menschen Nachrichten online lesen, geht es hier um News, aber natürlich hätte es auch um Online-Shops gehen können, oder Sport, oder oder.. Das Problem ist überall dasselbe. Tracking findet statt, damit das Modell ‚Daten gegen Informationen‘ funktioniert. Wenn wir uns einig sind, dass es nicht erstrebenswert ist, dass irgendwo Profile von uns existieren, die wir nicht beeinflussen und nicht mal korrigieren können, wenn sie fehlerhaft sind, dann muss über das Internet neu nachgedacht werden. Spätestens seit wir wissen, dass die besten Kunden der Profilsammler die Geheimdienste sind.
Trackography zeigt nicht nur, welche News-Sites wie tracken, sondern erklärt auch die Systematik dahinter, wie die Daten aufbereitet wurden: Meet the Trackers.
Die Visualisierung zeigt nicht in Echtzeit, welche Wege die Daten nehmen. Für jedes Land, für das bei Trackography Daten vorliegen, wurde im Land von Freiwilligen Skripte ausgeführt – alles legal und mit öffentlich verfügbaren Informationen – um den Weg der Daten nachzuvollziehen. Es sind viel mehr Länder geworden, als anfangs geplant war, aber es fehlen auch noch viele.
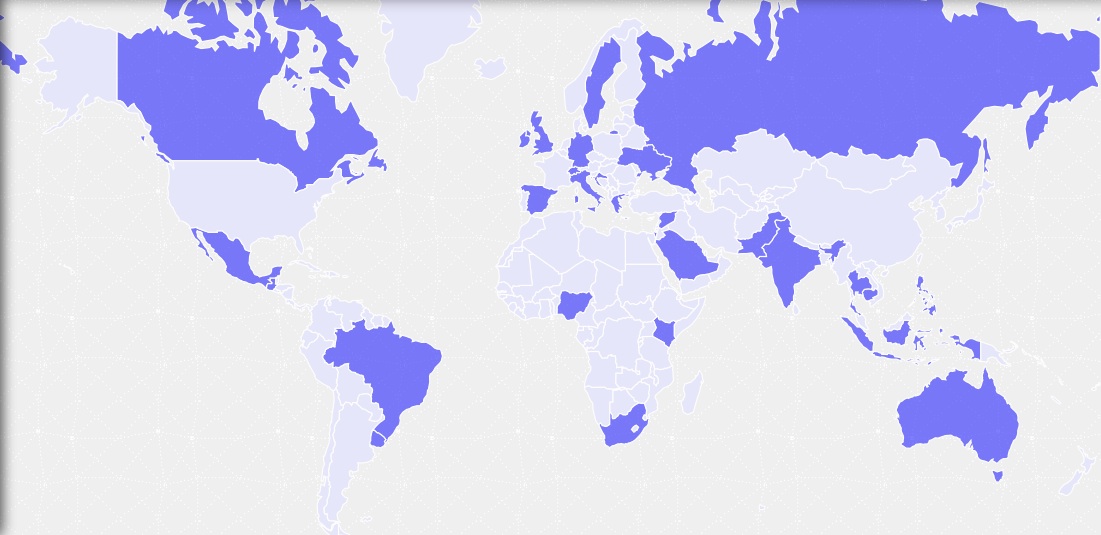 Eine „schöne“ Geschichte über Russland und die Ukraine wird im Talk erzählt, das Video steht unten. Das faszinierendste Beispiel aktuell: Syrien.
Eine „schöne“ Geschichte über Russland und die Ukraine wird im Talk erzählt, das Video steht unten. Das faszinierendste Beispiel aktuell: Syrien.
Wer Daten aus weiteren Ländern beisteuern kann, kann hier und hier weitere Informationen dazu finden, oder einfach eine Mail an trackmap@tacticaltech.org schicken.
Und schließlich gibt es natürlich auch viele Tips dazu, wie Ihr das Tracking reduzieren könnt: What can I do to prevent being tracked when reading the news online? mit den passenden Browser-Add-Ons dazu.
Ein paar Highlights aus der bisherigen Auswertung der Daten:
- 90% alles Nachrichten-Websites weltweit routen ihre Daten über US-Infrastruktur
- Die meisten Tracker finden sich bei
- Wall Street Journall
- Philippine Daily Inquirer
- Kashmir Times
- Libertad Digital, eine spanische News-Website, die für engagierten Journalismus steht, lässt 49 Firmen auf ihrer Seite tracken
- Einige deutsche News-Websites routen ihre Daten über Indien, das derzeit überhaupt kein Datenschutzgesetz hat
Wie die Daten gesammelt und ausgewertet werden, steht hier: Trackography methodology.
Der Talk beim Congress:
Es gibt auch eine Aufzeichnung des Talks ohne Tracker und die Präsentation ist ebenfalls online.
Viel Respekt dafür nochmal an Claudio Agosti, Maria Xynou und meinen Lieblingsdeveloper Niko Para.
Disclaimer: hier trackt die VG Wort und ein sehr eingeschränktes Piwik.
Bei netzpolitik.org gibt es eine leicht veränderte Fassung dieses Blogposts.
Pingback: [Annalist] Trackography: You never read alone – #31C3 | netzlesen.de
Wenn ich diese Seite aufrufe, zeigt Disconnect.me 12 blockierte verweise zu VG Wort und Google. Für alle, die beim Benutzen ihres Web-Browsers nicht verfolgt werden wollen empfehle ich die Nutzung von Firefox, DuckDuckGo, Diconnect, AdBlockPlus und NoScript. Mehr zum Thema findet sich hier http://donttrack.us/ und http://fixtracking.com/
Danke für den Hinweise: den VG-Wort-Cookie habe ich ja im Text explizit erwähnt, und Google/YouTube kommt halt vom eingebundenen YouTube-Clip des Talks.
Die Hinweise sind absolut richtig, und mehr Tips zu Add-Ons, die gegen Tracking helfen, finden sich ja in der ebenfalls im Text erwähnten Trackography-Seite https://myshadow.org/trackography-solutions.
Bei YouTube teilen sich die Geister: lieber mit YouTube-Clip, weil das eben doch am bequemsten ist, oder lieber nicht, um konsequent das Tracken zu verhindent? Oder darauf bauen, dass die, die wirklich keine Verbindung zu YouTube haben wollen, das über die diversehen Optionen sowieso schon deaktiviert haben?
Ich kann ansonsten auch noch das Add-On Cookie-Monster empfehlen, das macht es sehr einfach, die Cookies zu verwalten und je nach Fall zu de-/aktivieren.
…beinahe hätte ich es vergessen: BetterPrivacy darf auch nicht fehlen. Und natürlich sollten das Flash-Plug-In und das Java-Plug-In ausgeschaltet werden.